Durante il lavoro di tesi sono stati analizzati vari aspetti partendo dalla
trascrizione fino ad arrivare alla codifica del testo, dalle prime indicazioni
metatestuali all’adozione dello schema ad XML TEI e la conseguente fruizione
del testo con EVT.
Nello specifico, per la rappresentazione formale e strutturale del testo, è stato
seguito lo standard di codifica TEI P5 ed è a stato scelto di codificare i nomi di persona e di luogo.
L’elemento <teiHeader> corrisponde all’intestazione dell’intero manoscritto, all’interno della quale sono stati inseriti tutti i metadati descrittivi del manoscritto relativi alla provenienza, alla pubblicazione e alla descrizione.

Come elemento sottostante del <teiHeader> è stato inserito il tag <listPerson>, il quale contiene una lista di descrizioni, ciascuna delle quali fornisce informazioni relative a una persona specifica o a un gruppo di persone, per esempio i partecipanti a un’interazione verbale o le persone identificate da una fonte storica. Questo elemento appartiene al modulo “namesdates” descritto al capitolo 13 delle linee guida della TEI.
All’interno di <listPerson> sono state inserite le informazioni relative ad un personaggio specifico attraverso il tag <person> . La struttura dell’ elemento è la seguente:

Come si può notare, annidato al tag <person> è presente l’elemento <persName> , il quale descrive un nome proprio o un sintagma identificabile come nome proprio. Nel contesto del lavoro di tesi, l’elemento è ripetuto due volte: una volta per la lingua latina e una volta per la lingua italiana. I due elementi si distinguono grazie all’attributo @xml:lang che riporta la lingua dell’elemento utilizzando i codici tratti da RFC 3066. Per il latino abbiamo:
@xml:lang=”la” e per l’italiano @xml:lang=”it”.
Al tag è stato associato un @xml:id che assegna un identificatore univoco all’elemento a cui è associato l’attributo. Questo è utile perché nel testo i nomi di persona sono ripetuti più di una volta e attraverso l’attributo @ref (reference) è possibile indicare esplicitamente una definizione o identità completa per l’entità nominata mediante uno o più URI, che sono identificatori di significato (Uniform Resource Identifier).
Per quanto riguarda la codifica dei luoghi, le considerazioni sono simili:
l’elemento <listPlace>, appartenente anche al modulo “namesdates”,contiene una lista di luoghi, eventualmente seguita da una lista di relazioni tra questi. All’interno della lista, ogni luogo è definito come segue:

All’interno del tag <place>, che contiene informazioni relative ad un luogo geografico, sono presenti due tag <settlement> e tre tag <placeName> .
L’elemento <settlement> contiene il nome di un insediamento quale una città o un comune considerati come unità geopolitica o amministrativa. L’attributo @type caratterizza l’elemento utilizzando una classificazione o tipologia funzionale.
L’elemento <placeName> contiene l’indicazione assoluta o relativa di un
nome di luogo. @xml:id – @ref – @xml:lang sono uguali alle trattazioni fatte perle
liste dei nomi di persona.
Perché le liste del < teiHeader> possano trovare una corrispondenza con le numerose occorrenze nel testo, è necessario che ciascun entità nominata venga annotata con un preciso elemento. Nello specifico, è importante che ogni persona sia codificata all’interno di un <persName> e ogni luogo all’interno di un <placeName>. Il collegamento tra le singole voci della lista e i nomi presenti nel testo è reso possibile grazie all’utilizzo di un attributo @ref , al quale dovrà essere dato come valore l’ @xml:id corrispondente preceduto dal simbolo cancelletto ( #), per rispettare il tipo di dato previsto dalle linee guida e dalla sintassi XML.
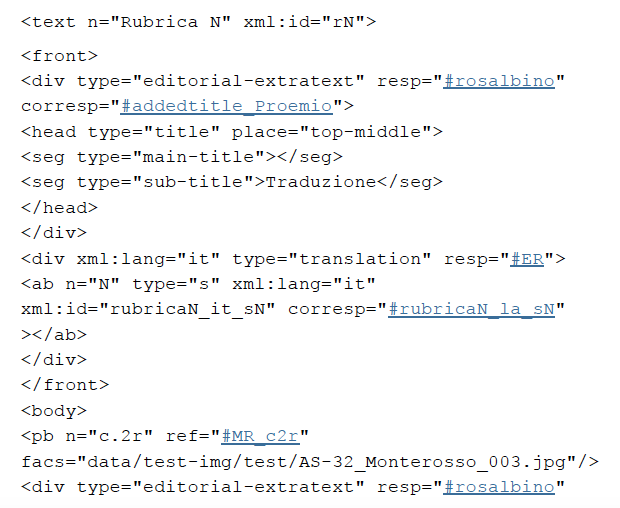
Suddivisione in Rubriche
Il manoscritto è suddiviso in rubriche e nella codifica è stata rispettata la
divisione originale. Per rispettare la suddivisione originale è stato usato il tag <text> che
contiene un unico testo di qualsiasi tipo, sia esso unitario o composito.
La struttura generale è la seguente:

<front>
Prima della trascrizione del testo vero e proprio, ogni <text> è arricchito da una serie di informazioni che forniscono dettagli di vario tipo sul documento.
Queste indicazioni sono raggruppate nell’elemento <front> , identificato da un @xml:id . Il peritesto iniziale contiene qualsiasi materiale (intestazioni, frontespizio, prefazioni, dediche, etc.)
<body>
Allo stesso livello gerarchico del <front> c’è il <body>, l’elemento che contiene l’intero corpo del documento. Al suo interno, le diverse informazioni sono state codificate per mezzo di numerosi elementi. Prima di passare alla loro descrizione, però, bisogna fare una distinzione tra elementi strutturali e semantici. I primi, si occupano di riprodurre la struttura originaria del testo (in paragrafi, in versi, ecc.) nel documento elettronico; i secondi, invece, sono utilizzati per marcare semanticamente i contenuti ricercati.
<div>
Un breve riassunto del documento dotato di tutte le informazioni necessarie per una rapida comprensione dei contenuti. Il <div> suddivide gli spazi in zone, permettendo di ordinare il progetto in modo semplice e dettagliato.
<head>
Contiene qualsiasi tipo di titolo, per esempio il titolo di una sezione, di una lista, di un glossario, di una descrizione di manoscritto, ecc.
<seg>
Contiene una qualsiasi unità testuale a livello sintagmatico, ivi compresi altri elementi del tipo <seg>.
<ab>
Contiene una qualsiasi unità testuale a livello di componente che funge da contenitore anonimo di sintagmi o elementi interlivello simili al paragrafo, ma senza il bagaglio semantico di quest’ultimo.
<pb>
L’elemento <pb> è si interessa soprattutto della gerarchia di codice poiché al cambio pagina non si sarebbe riuscito a recuperare il relativo testo. Quando in EVT si vuole cambiar pagina si va sul modello che ci indicherà il numero corrente in cui ci troviamo. All’interno del software EVT la pagina c.2r a noi è ripetuta, essa fa parte di una gerarchia sovrapposta che è legata al cambio di rubrica. La rubrica 1 parte alla stessa pagina del proemio quindi per evitare una perdita di informazione nel modello dati di EVT, si è fatto in modo di ripetere la pagina. Questo dato è inserito esclusivamente per far funzionare EVT,
poiché, quando c’è un nuovo text, EVT non mantiene il dato precedente. Al fine di inserire la codifica all’interno del software EVT, sono stati apportati degli interventi funzionali, legati alle gerarchie sovrapposte, e poiché si è codificato un testo per ogni rubrica, il modello dati non gestisce il cambio pagina, o la storia della pagina corrente.
<lb>
segna l’inizio di una nuova riga (tipografica) in qualche edizione o versione di un testo.
La trascrizione del testo è divisa in <lb> all’interno di un <div>.
Per quanto riguarda @xml:id del tag <lb>, la struttura è
“rubrica1_c2r_la_L6”,
quindi c’è la rubrica in cui ci troviamo al momento (rubricaN), il riferimento all’immagine (c2r), la lingua in cui è il testo trascritto (la) e la riga trascritta (L6)
Il testo in italiano si trova direttamente all’interno del tag <ab>, in cui sono presenti una serie di attributi:
@n=”1″ → dato che anche il testo in italiano è diviso in periodi testuali, questo indica dove ci troviamo
@type=”s” ovvero “sentence”
@xml:lang=”it” quale lingua è
@xml:id=”rubrica1_it_s1″ → per fare questo Id si mette la rubrica in questione, la lingua (it) e il periodo in questione(s1)
@corresp =”#rubrica1_la_s1″ qual è il periodo in latino che corrisponde.